1 Introduction
This introduction gives a brief summary of the advantages and possibilties that data binding offers and how they can be leveraged using JBind.
1.1 Consistency
When writing applications that process XML data a common problem is to ensure consistency between the XML data and the code that processes the data. Validating XML parsers play an important role here because they can check that XML data is valid according to its schema. Yet, they can not guarantee that the code that does the further processing is prepared to process that kind of data.
This is where data binding comes in. Data binding takes as its input a schema and generates code that reflects the schema. In other words, data binding is a means to transport the information contained in a schema into programming languages. Thereby consistency between a schema and its processing code is guaranteed.
In general, the more complicated the XML data is the more difficult is to ensure the consistency. JBind supports nearly 100% of the XML schema recommendation. Therefore it can be used in situations with rather complex XML data.
1.2 Adding Behaviour to Data
XML schema is a great possibility to describe the data aspect of an application. Yet, that data has no behaviour (or semantic/meaning). One possibility to add behaviour is to add it from "outside" by having code that interprets the data. Data binding allows another possibility namely to add behaviour directly to the data. This is done by augmenting the generated code with methods.
Having data and its behaviour together the result is nothing else than objects in terms of object oriented programming. At this point it is of great advantage that XML schema is object oriented with respect to two central features: inheritance and polymorphism. This allows a natural mapping of XML schemas into object oriented code.
JBind introduces the concept of XML code that allows the seamless integration of manually implemented behavioural code with generated code that reflects the data aspect (cf. 6 XML Code). Having XML data augmented with behaviour lots of possibilities open for developers.
1.3 XML Meta Data
This topic is closely related to the first two mentioned topics namely "Consistency" and "Adding Behaviour to Data" but adds another twist. Several reasons cause the usage of XML meta data in applications:
-
Information that is explicitly available in form of XML meta data can easily be used by different parts of an application. Thereby meta data can help to guarantee the consistency between different parts of an application. (Think of a web application where some HTML input fields must match the fields in a relational database.)
-
Information that is available explicitly in form of meta data is less error-prone than the same information contained implicitly in (lots of) source code. If meta data is stored in XML documents then it can be validated using a parser.
-
Meta data makes applications configurable thereby allowing non-programmers to modify the application. If the configuration data also contains behaviour then the applications are also easily extensible.
Conventional applications that use meta data are often more complicated at first sight than corresponding
hardwired applications because the use of meta data comes with additional complexities.
JBind eases the use of meta data essentially. The ability of JBind to generate methods
that access referenced data (reflecting attributes of type IDREF and IDREFS or keyref
constraints) allows to adequately handle not only meta data that has a simple hierarchical
structure but also meta data that has an arbitrary structure.
There is no more reason to hardwire specific data and behaviour in applications.
1.4 Domain Specific Languages and Application Frameworks
In case that not only a single application is to be developed but a whole family of applications the use of a domain specific language bears lots of advantages. XML schema can be used to describe the syntax of a domain specific language and JBind can be used to define its (operational) semantic by adding behaviour code.
The extensibility mechanisms of XML schema allows to carry on this idea to full fledged application frameworks. An application framework can be defined by an XML schema with the types having default behaviour. An instance document of the framework schema corresponds to an (executable) application. The framework schema can easily be extended by deriving new customized types from the framework types and using them in framework instance documents.
Note:
The development of a Web-Application framework based on JBind may be a promising endeavour. In fact, the author has already gathered quite an experience in developing a Web-Application framework using similar ideas.
1.5 Processing
At the time being most people familiar with XML techniques agree that XML is the ideal way to exchange data between applications whereas the use of XML inside applications is not that clear. Using generic data structures like [DOM] is awkward. Therefore applications often internally use data structures that are better suited for their processing needs but have to be converted into XML when they are to be exchanged.
JBind allows to have data structures that are well suited for internal processing and that are in an XML form at the same time. Another benefit of having the internal data in an XML form is the ease of using powerful XML techniques like XPath/XSLT not only for exchange (and rendering) but also for internal processing (cf. 5.2.3 XPath Methods and 6.3 Maze Game for an XSLT example).
1.6 A Word of Care - Relating JBind to other Data Binding Frameworks
The main focus of JBind is to ease the intergration of manually written code with generated code and to support nearly all of the XML schema specification. Performance is not a primary design goal of JBind.
Java-XML data binding links the Java world with the XML world. Most data binding frameworks have a major focus on the Java part of the story whereas the XML part is often a compromise with respect to complexity, usability, and performance. JBind clearly has its focus on the XML part which caused some compromises at the Java side.
Yet, JBind allows to plug-in so called cartridges that are responsible for code generation. The cartridges are provided with easily usable information about the schemas to be processed. Developers interested in developing/contributing new cartridges may contact the author.
2 Using JBind
JBind contains the following classes that provide easy access to its functionalities:
| class | description |
|---|---|
org.jbind.xml.schema.compiler.Compiler |
Compiles XML schemas. |
org.jbind.xml.facade.Validator |
Validates XML schemas and instance documents. |
org.jbind.xml.ant.CompileTask |
Ant task for compiling schemas (cf. 3.2 Invoking the Schema Compiler). |
org.jbind.xml.ant.ValidateTask |
Ant task for validating schemas and instance documents. The documents to validate can be specified by a
file attribute, a url attribute, or a nested fileset. The isXsd
attribute determines if documents are checked to be a valid schema or a valid instance document. If the
isXsd attribute is not specified then documents whose name end with ".xsd" are
assumed to be schema documents whereas all other documents are assumed to be instance documents.
|
org.jbind.xml.ant.ExecuteTask |
Ant task for executing application code. |
org.jbind.xml.facade.JBindFacade |
Provides easy access to JBind functionalities. The functionalities include marshalling, unmarshalling, validation, data comparison, creation of SAXSources to output data, configuration, and application execution. |
org.jbind.xml.code.IApplicationCode |
Encapsulates XML applications. |
org.jbind.xml.code.IConfigurationCode |
Encapsulates XML configuration code. |
org.jbind.xml.schema.cmp.Schemas |
Singleton that provides access to schemas within the virtual machine. |
org.jbind.xml.Config |
Configures JBind. |
JBind uses an XML parser of its own to access XML data. This parser supports the [Namespace 1.1] and [XInclude] candidate recommendations.
3 Schema Compiler
The schema compiler processes a schema by generating classes/interfaces for the types contained in the schema. Element and attribute declarations contained in types are reflected by corresponding accessor methods. The generated sources can be placed into different subpackages corresponding to the different symbol spaces of XML schema. There are 5 relevant symbol spaces: types, attributes, elements, attribute groups, and element groups (model groups).
Global types are mapped into classes/interfaces in the types subpackage. An anonymous type that appears inside a local attribute or element declaration is mapped into a static inner class/interface inside the class/interface of the type that contains the declaration. If an anonymous type appears inside a global attribute or element declaration then the class/interface for that type is generated in the subpackage for attributes/elements. If anonymous inner types appear inside an attribute group or element group then a container class is created for the group (in the corresponding subpackage) that contains the static inner classes/interfaces of all anonymous types contained in that group.
3.1 Generated Sources
Given an XML schema four kinds of sources are generated:
|
|
Note:
In principle, the code generation is configurable by so called cartridges. [Definition: A cartridge can be plugged into the schema compiler and is responsible for generating a certain kind of source.] Currently there are 4 cartridges corresponding to 4 kinds of generated sources. However, this part of JBind is not well documented and has to mature. This might be a further direction of development of JBind if the user community demands that feature.
The graphic contains the UML diagram of an example that shows the relationship between the four kinds of generated sources. The schema of this example is presented in section 3.4 Example Schema. The names of interfaces have the prefix "I" and the names of data classes/interfaces have the suffix "Data". The graphic demonstrates that the behaviour class/interface of a type can be missing. In this case the inheritance hierarchy uses the next available class/interface that follows in the hierarchy. An abstract type is also contained in the example for which no data class is generated.
 |
The design goal of the inheritance hierarchy was to have a separation between the always generated parts that reflect the data aspect of a type and the manually implemented parts that add behaviour. (The methods declared in data interfaces are already available for usage in the derived behaviour classes.)
3.2 Invoking the Schema Compiler
The schema compiler is invoked by the command line:
java org.jbind.xml.schema.compiler.Compiler -schemaUrl <url> [-validateOnly] [-package <package>] [-destinationDir <dir>] [-dataDir <dir>] [-behaviourDir <dir>] |
schemaUrl: A url to an XML schema.validateOnly: If specified then the schema and code generation is validated only. No code is output.package: The Java package that contains the generated classes/interfaces.destinationDir: Used for data and behaviour classes/interfaces if no more specific directory is specified.dataDir: Used as destination directory for data classes/interfaces.behaviourDir: Used as destination directory for behaviour classes/interfaces
url: A url to an XML schema.file: A file containing an XML schema.package: The Java package that contains the generated classes/interfaces.destinationDir: Used for data and behaviour classes/interfaces if no more specific directory is specified.dataDir: Used as destination directory for data classes/interfaces.behaviourDir: Used as destination directory for behaviour classes/interfaces-
derivePackages: Boolean attribute that is only relevant if file sets are used. The default isfalse. If this attribute isfalsethen the schemas selected by file sets get the package specified by thepackageattribute. If this attribute istruethen the package of a schema contained in a file set is derived from its relative location in the file set. In other words, the subdirectory hierarchy of a file set is translated into a corresponding package hierarchy.
taskdef element must contain the JBind library and the necessary external libraries (cf. A Installation).
<taskdef name="jbind" classname="org.jbind.xml.ant.CompileTask" classpathref="jBind"/>
<target name="xml98Schema" depends="taskDef">
<jbind url="http://www.w3.org/2001/xml.xsd" destinationDir="${genSrcDir}"/>
</target>
<target name="generateExamples" depends="taskDef">
<jbind dataDir="${genExamplesSrcDir}" behaviourDir="${examplesDir}" derivePackage="true">
<fileset dir="${examplesDir}" includes="**/*.xsd"/>
</jbind>
</target>
|
3.3 Parameterizing the Code Generation
Code generation is mainly parameterized by attributes that appear inside schema documents.
XML schema allows the appearance of arbitrary attributes at nearly all tags
as long as they do not belong to the http://www.w3.org/2001/XMLSchema namespace. This feature is used in JBind
to add binding information to schemas. [Definition:
Let the JBind namespace be "http://www.jbind.org"].
[Definition: A binding attribute
is an attribute that belongs to the JBind namespace.] All binding attributes are
declared in the JBind schema jBind.xsd.
It is possible to have a schema and its binding information in separate documents. This approach is explained in section 3.5 Schema Adjunct Documents. However, this approach consists of generating a new schema based on an original schema by augmenting it with binding information. The result is a schema that contains the binding attributes that are described in this section.
[Definition: Some binding attributes have an effect only on the tag at which they appear. They are called local binding attributes.] [Definition: Other binding attributes are propagated along nested tags. They are called propagating binding attributes.] In general, local binding attributes are only allowed on dedicated tags for which they bear binding information whereas propagating binding attributes may appear on any tag. Finally there are [Definition: defaulted binding attributes that take their default value from the schema element they are nested in. If a schema is included by another schema then the including schema is also considered.]
The situation is slightly more complicated for attribute and element declarations that are references to other declarations. In this case if a binding attribute is accessed then first the binding attributes of the declaration itself are considered and then - only if no matching attribute was found - the binding attributes of the referenced declaration.
[Definition: All classes/interfaces that are generated for a schema are placed into a common package that is called the schema package]. The schema package can be specified by
an argument on the command line,
a local binding attribute on the
schematag, ora mapping of namespaces to package names in the JBind configuraiton (cf. 7.6 Namespace to Package Mapping).
schema tag that in turn overrules the namespace to package mapping.
If the name of a type contains one or more dots then the name is split into two parts: 1. A prefix reaching until the last dot and 2. a suffix starting after the last dot. The prefix is used to denote a subpackage inside the schema package whereas the suffix is used for the names of the generated classes/interfaces inside their package.
3.3.1 Symbol Space Subpackages
The generated code can be placed into different subpackages depending on symbol spaces. Five binding attributes determine the subpackages. These binding attributes can occur inside a schema tag.
| attribute | default |
|---|---|
typeSubPackage | |
attributeSubPackage | attribute |
elementSubPackage | element |
attrGroupSubPackage | attrGroup |
elemGroupSubPackage | elemGroup |
Note:
The default configuration uses no subpackage for (global) types. This means their files are placed direclty in the schema package. In order to avoid name conflicts, the files of all other symbol spaces are placed in subpackages of their own. If other symbol spaces are also placed directly in the schema package by assigning an empty string to the corresponding binding attribute then care must be taken that the names do not conflict.
3.3.2 Prefixes and Suffixes for Class/Interface Names
The prefixes and suffixes used for the various generated sources can be configured by 8 binding attributes that
can appear in the schema tag.
The names of these binding attributes are created by selecting an entry from the cartridge column in the following
table and appending
either "Prefix" or "Suffix". For example to set the data class prefix the binding attribute
dataClassPrefix is used. The table shows the default values for these binding attributes.
| cartridge | prefix | suffix |
|---|---|---|
dataInterface | I | Data |
dataClass | Data | |
behaviourInterface | I | |
behaviourClass |
3.3.3 Accessor Methods
Several binding attributes control the generation of accessor methods.
[Definition: Accessor methods are based on the properties of a type,
i.e. on its attribute/element declarations and on its reference constraints]. [Definition: Each property has a property name. In case
of an element/attribute declaration the property name is equal to the name of the declaration.
In case of a reference constraint the name is either equal to the name if the referencing attribute
or to the name of the reference constraint. Property names may be overloaded by the name binding
attribute.]
The names of the generated methods are of the form "<prefix><propertyName>" where the
first letter of the property name is capitalized.
Some binding attributes determine if specific methods are generated and in what form.
These attributes are propagating binding attributes.
They can take one of three possible values: normal, hook, or none.
The value normal causes the generation of
matching method declarations in the data interfaces and method
implementations in the data classes. The value hook
causes that method declarations are generated in the data interfaces like in the "normal"
case. The difference is that these methods are not implemented in the data classes.
Instead, the names of the generated methods in the data classes have the prefix "do" indicating that
they are hook methods. The actual methods have to be implemented manually in the
behaviour classes. Normally these implementations will
use the generated hook methods.
The following table gives an overview of these binding attributes together with their default values and prefixes of the generated methods.
| attribute | default | prefix | description |
|---|---|---|---|
getter | normal | get | Gets an attribute or element. Generated only for elements that have a maxOccurs of 1. |
setter | none | set | Sets an attribute. |
creator | none | create | Creates an element. |
creatorWithType | none | create | Creates an element. Allows to specify the type of the element (the so called overloading type). The overloading type must be a subtype of the declared element type. |
remover | none | remove | Removes an attribute or element. Generated only for elements that have a maxOccurs of 1. |
checker | none | has | Checks the presence of an attribute or element. Generated only for elements that have a maxOccurs of 1. |
iterator | normal | iter | Iterates the items of list valued attributes or elements. Generated only for attributes that have a list type and elements that have a maxOccurs greater than 1. If elements are iterated then the method name uses the plural form of the property name. |
refGetter | normal | ref | Gets referenced data. Data is referenced by attributes of type IDREF or by types that have a keyref constraint (cf. 5.2.1 Identity Constraints on Types). |
refsIterator | normal | refs | Iterates referenced data. Data is referenced by attributes of type IDREFS or by types that have a keyref constraint (cf. 5.2.1 Identity Constraints on Types). |
Note:
No accessor methods are generated for wildcard attributes or wildcard elements. They can be accessed by inherited methods (cf. 4.4.3 Wildcard Attributes and Elements).
Note:
If a type has an identity constraint then either a reference getter or a reference iterator method may be generated depending on the selector XPath. If the selector XPath is guaranteed to return only one data object then a getter method is generated and an iterate method otherwise. The analysis if the selector XPath returns only a single data object depends on the used XPath implementation (cf. 7.4 XPath). The analysis may be very sophisticated or may simply check if an XPath equals ".".
Note:
Elements of type IDREF or IDREFS also reference data. Yet, no special accessor methods are generated
because the corresponding methods are already defined in the interfaces
IIDREFData and
IIDREFSData.
In other words, to access data objects that are referenced by elements of type IDREF
or IDREFS first the elements must be accessed and then the corresponding
methods of the elements must be called.
Other binding attributes control the types used for accessor methods:
| attribute | occurrence | description |
|---|---|---|
useDataClass |
propagating binding attribute |
Boolean attribute that determines if the data class or the
simple storage type of an accessed property is used.
If set to true then the data class is used. If set to false (that is the
default) then the simple storage type is used if the property is an attribute or an element with
a simple type. If an element has a complex type then its data class is used regardless of the
useDataClass attribute.
If a property with a primitive Java type is iterated then the corresponding wrapper class is used
(e.g. a double is wrapped in a Double object).
Attribute setter methods always use the simple storage type.
|
referencedType |
attribute declarations, type key, type unique, and type keyref constraints (cf. 5.2.1 Identity Constraints on Types), fetch XPath method (cf. 5.2.3 XPath Methods) | Determines the type that is returned by reference getter methods. |
Note:
If the useDataClass binding attribute is set to false then the generated methods access
the simple storage values. In case that a simple storage value
has a primitive Java type a NullPointerException is raised if the accessed
attribute or element is not present. It is recommended to generate check methods
that can be called before such a simple storage value is accessed. In case that a simple storage value
has a reference type and but its attribute or element is not present null is returned.
3.3.4 Other Binding Attributes
| attribute | occurrence | description |
|---|---|---|
hasBehaviour |
defaulted binding attribute |
Boolean attribute that controls the generation of behaviour interfaces
and behaviour classes. The default is false.
|
name |
all "named" tags and enumeration facet tags |
Changes the name that is used for code generation. If this attribute is not specified
then the XML schema name attribute is used or - in case of anonymous types -
an automatically generated name. In case of enumeration facets the names of the generated
Java constants can be set. If no name is specified then the
constant name is derived from the value by converting all lower case letters into upper case letters
and by replacing invalid characters by underscores.
|
package |
schema and import tag | Determines the package of the generated classes/interfaces. |
factoryType |
schema tag | Determines the type of the schema factory. |
Note:
All names that are used in generated code are translated into valid Java identifiers. This translation simply replaces invalid characters by underscores. If a name starts with a character that would be valid inside a Java identifier (e.g. a number) but that is not valid at the beginning then the name is prefixed by an underscore.
3.4 Example Schema
The following example schema shows the usage of various binding attributes.
Looking at the UML diagram presented previously shows that no data class
is generated for the MeansOfTransport type and that no
behaviour class and no behaviour interface
for the Automobile type. This is caused by the fact that the MeansOfTransport type
is defined to by abstract and that the Automobile type is defined to have no behaviour.
The attribute manufacturer of the Vehicle type is of type IDREF.
This causes the schema compiler to generate the method
"IManufacturerData getManufacturer()"
to access the referenced manufacturer.
<?xml version="1.0" encoding="UTF-8"?>
<schema
elementFormDefault="qualified"
targetNamespace="meansOfTransport"
xmlns="http://www.w3.org/2001/XMLSchema"
xmlns:jb="http://www.jbind.org"
xmlns:t="meansOfTransport"
jb:package="meansOfTransport"
jb:elementSubPackage=""
jb:hasBehaviour="true" jb:setter="normal" jb:checker="normal"
jb:factoryType="Factory">
<complexType name="MeansOfTransport" abstract="true">
<annotation>
<documentation xml:lang="x-javadoc"><![CDATA[
Base class for all kinds of <i>means of transport</i>.
]]></documentation>
</annotation>
</complexType>
<complexType name="Vehicle">
<complexContent>
<extension base="t:MeansOfTransport">
<attribute name="numberOfWheels" type="int"
jb:setter="hook" jb:remover="normal">
<annotation>
<documentation xml:lang="x-javadoc">
This attribute is set by a hook method that is manually implemented
in the {@link Vehicle} class.
</documentation>
</annotation>
</attribute>
<attribute name="manufacturer" type="IDREF" jb:referencedType="t:Manufacturer"/>
</extension>
</complexContent>
</complexType>
<complexType name="Automobile" jb:hasBehaviour="false">
<complexContent>
<extension base="t:Vehicle">
<attribute name="fuelType" type="string" use="required" jb:checker="none"/>
<attribute name="consumptionInLitres" type="decimal" jb:name="consumption"/>
<sequence>
<element ref="t:engine"/>
</sequence>
</extension>
</complexContent>
</complexType>
<complexType name="Truck">
<complexContent>
<extension base="t:Automobile">
<attribute name="loadCapacityInTons" type="decimal"/>
</extension>
</complexContent>
</complexType>
<element name="meansOfTransport" type="t:MeansOfTransport" abstract="true"/>
<element name="vehicle" type="t:Vehicle" substitutionGroup="t:meansOfTransport"/>
<element name="automobile" type="t:Automobile" substitutionGroup="t:vehicle"/>
<element name="truck" type="t:Truck" substitutionGroup="t:automobile"/>
<element name="engine"/>
<complexType name="Manufacturer" jb:hasBehaviour="false">
<attribute name="id" type="ID"/>
</complexType>
<element name="manufacturer" type="t:Manufacturer"/>
<element name="manufacturers">
<complexType>
<sequence maxOccurs="unbounded">
<element name="manufacturer" type="t:Manufacturer"/>
</sequence>
</complexType>
</element>
<element name="meansOfTransports">
<complexType>
<sequence maxOccurs="unbounded">
<element ref="t:meansOfTransport"/>
</sequence>
</complexType>
</element>
<!--
Factory type that has creation methods for vehicles, automobiles, trucks, and manufacturers.
The content model of a factory may contain only references to top-level element declarations.
-->
<complexType name="Factory" jb:hasBehaviour="false" jb:getter="none" jb:creator="normal">
<sequence>
<element ref="t:vehicle"/>
<element ref="t:automobile"/>
<element ref="t:truck"/>
<element ref="t:manufacturer"/>
</sequence>
</complexType>
</schema>
|
See the sources and the JavaDoc. The vehicle class is inserted here for convenience to show an example of a hook method:
package org.jbind.example.meansOfTransport;
import org.jbind.xml.msg.XmlException;
public abstract class Vehicle extends MeansOfTransport implements IVehicle {
/**
* Implementation of the setter using the hook method.
*/
public void setNumberOfWheels(int anInt) throws XmlException {
doSetNumberOfWheels(anInt);
}
/**
* Declaration of the hook method. The hook method is implemented by the
* generated data class.
*/
protected abstract void doSetNumberOfWheels(int anInt) throws XmlException;
}
|
3.5 Schema Adjunct Documents
Section 3.3 Parameterizing the Code Generation showed how binding attributes are included in schema documents to parameterize the code generation. This approach works fine if the schema to be bound can be modified to fit the needs of JBind. If a schema can not be modified or the schema is to be shared by several parties with some of them not using JBind then another approach is needed that leaves schema documents untouched.
[Definition: Schema adjunct documents are used by JBind to store binding information for schema documents in separate documents.] This has the advantage that schema documents have not to be touched and that binding information is not scattered all over schema documents. Schema adjunct documents are governed by the jBind-schema-adjunct.xsd schema from which a part is repeated here for convenience:
<complexType name="Adjunct">
<choice minOccurs="0" maxOccurs="unbounded">
<any namespace="http://www.jbind.org" processContents="strict"/>
<element name="adjunct" type="t:Adjunct"/>
</choice>
<attribute name="select" use="required">
<simpleType>
<restriction base="string">
<pattern value="[^/].*"/>
</restriction>
</simpleType>
</attribute>
<attribute name="checkForEmptySelection" type="boolean" default="true"/>
<anyAttribute namespace="http://www.jbind.org" processContents="strict"/>
</complexType>
<element name="adjuncts">
<complexType>
<sequence>
<element name="adjunct" type="t:Adjunct" minOccurs="0" maxOccurs="unbounded"/>
</sequence>
</complexType>
</element>
|
A schema adjunct document contains arbitrarily nested adjunct elements. Each adjunct
element has a required select attribute that holds a relative XPath to select parts of a schema
document. The XPaths of top-level adjunct elements are evaluated relative to the document root of
a schema document whereas the XPaths of nested adjunct elements are evaluated relative to the
selected parts of their parent adjunct elements. The optional checkForEmptySelection
attribute controls if an adjunct element with an empty selection is reported. This attribute is useful
to detect errors in adjunct documents.
An adjunct element can bear arbitrary binding attributes.
and can contain arbitrary extension elements.
These are copied into the parts of a schema document that are selected by the corresponding adjunct element.
Binding attributes are directly copied whereas extension elements are copied into an annotation/appinfo
element. If a selected part has already an annotation element then an additional appinfo
element containing the extension elements is appended to the content of the annotation element.
The current implementation for processing schema adjunct documents consists of generating new schema documents. [Definition: A bound schema is the result of applying binding information contained in a schema adjunct document to a schema document.] A bound schema can be registered in the JBind configuration to be used whenever its original schema is addressed (cf. 7.7 Entity Resolver, Import, and Include).
The process of applying binding information contained in schema adjunct documents to schema documents is implemented by a 2 step stylesheet transformation. In the first step, a schema adjunct document is transformed into a stylesheet called the adjunct stylesheet that contains all binding information and knows how to process schema documents accordingly. In the second step, the adjuct stylesheet is applied to a schema document. In principle, a schema adjunct document can contain binding information for several schemas and a schema may be bound by applying several schema adjunct documents sequentially.
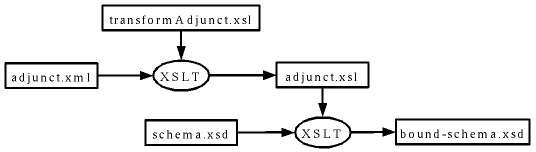
This process is illustrated in the next figure. The schema adjunct document adjunct.xml is
transformed into the adjunct stylesheet adjunct.xsl by the
transformAdjunct.xsl
stylesheet. Then the adjunct stylesheet is used to transform the schema document schema.xsd
into its bound version bound-schema.xsd.
 |
4 Data Model
4.1 Datatype Hierarchy
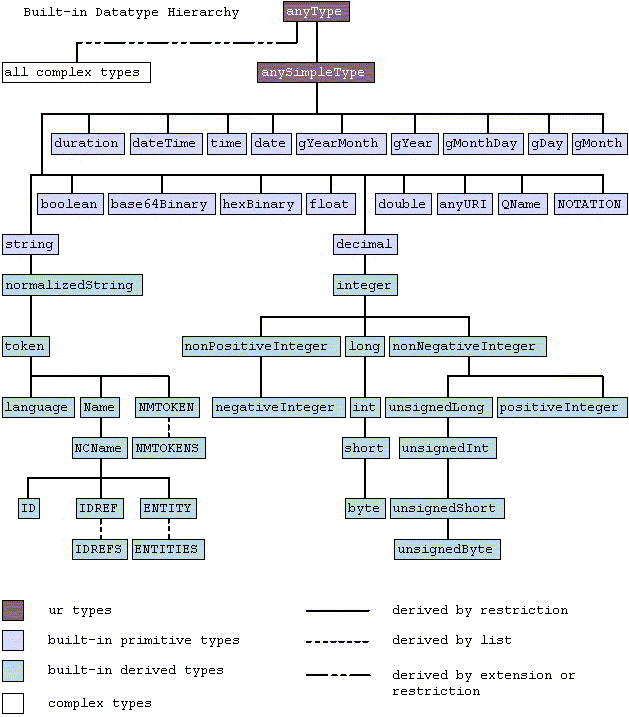
The datatype hierarchy of XML schema is defined in chapter built-in datatypes in the XML schema specification. A graphic from that chapter is inserted here for convenience.
 |
Datatypes are represented internally by instances of generic type classes. These classes are instantiated either in static setup code (for the built-in types) or when a schema is read in. The corresponding interfaces can be found in the package org.jbind.xml.core.type.
[Definition: Data types that are derived from
anySimpleType have a simple storage type.
This is the type used to store values of the corresponding type.
Simple storage types are either primitive types (like int or double) or
they are (simple) reference types (like String or BigDecimal).]
Types that are not derived from a simple type, i.e. complex types with a complex content model
have no simple storage type. Complex types with a simple content model have the same simple storage
type as their content type.
4.2 Data Storage
[Definition: Classes/interfaces that are responsible for the storage of values are called storage classes/interfaces]. [Definition: Corresponding to the datatype hierarchy there is a hierarchy of these classes/interfaces that is called the storage hierarchy]. The framework contains interfaces for all built-in storage classes that can be found in the package org.jbind.xml.core.data.
The data classes/interfaces that are generated by the schema compiler are derived from storage classes/interfaces. In other words, each generated class/interface has an ancestor amongst the classes/interfaces of the package org.jbind.xml.core.data. This also true for data classes/interfaces of complex types. If a complex type has complex content then it is derived from anyType. If the type has simple content then its storage class/interface is derived from the storage class/interface of its simple content type.
[Definition: Each storage class whose type is
derived from anySimpleType has a simple storage value.
A simple storage value is for example an int or a String.]
The simple storage values can be accessed by getter and setter methods of the
storage classes.
For example the interface of the int storage class is:
/*
* JBind
*
* Copyright (c) by Stefan Wachter. All rights reserved.
*
* Usage, modification, and redistribution is subject to license terms that are
* available at 'http://www.jbind.org'. The JBind license is like the
* 'Apache Software License V 1.1'.
*/
package org.jbind.xml.core.data;
import org.jbind.xml.msg.XmlException;
public interface IIntData extends ILongData {
int getInt();
void setInt(int aValue) throws XmlException;
}
|
The storage classes can be called wrapper classes for the simple storage values. The reason for introducing wrapper classes is that the datatype hierarchy should be reflected by the storage hierarchy.
Note:
There are subtle problems when mapping the built-in XML datatypes into corresponding Java classes.
Consider the XML byte type that is a restriction of the XML short type that in turn
is a restriction of the XML int type until the anySimpleType is reached.
The storage class of the XML byte type
has as its simple storage type the primitive Java
type byte. Accordingly, it has the accessor methods "byte getByte()" and
"void setByte(byte aByte)".
The XML byte type
must also have the accessor methods "int getInt()" and "void setInt(int anInt)"
because it is derived from the XML int type.
These methods are implemented by casting integers into bytes and vice versa. Similar conversions have
to be done all the way up in the storage hierarchy.
Another problem is that two simple values can be equal only if they have the same built-in primitive
type or if their types are derived from the same built-in primitive type. Simple values whose types
are not derived from or equal to the same built-in primitive type can not be equal.
For example the decimal 123.0 is equal to the byte 123 but is not equal to the string "123".
In addition, values that are equal must have the same hash code in order to be usable as keys in hash maps.
4.3 Implementation
The implementation of the storage hierarchy is based on the Bridge Pattern (cf. [GOF]). This pattern consists of an abstraction that uses an implementation. In case of JBind the data classes are the abstraction that is backed by default by a simple nested HashMap structure that plays the role of the implementation. [Definition: The implementation is called the data implementation]. It can be configured by specifying the data implementation factory. (cf. 7.5 Data Implementation Factory).
The data implementation of a
data class is accessed using its getImpl_() method.
It may be useful to access the underlying data implementation directly for example in order to
apply a stylesheet.
Note:
The design decision of using the brige pattern has the advantage that the data classes are decoupled from the underlying data structure. For example it is possible to use an also provided [DOM] implementation instead of the simple HashMap implementation. The advantage of using the DOM implemtation is that a ready to use DOM tree is always in memory. Yet, the disadvantage of the DOM implementation is that it is less performant.
4.4 Manipulating XML Data
XML data should be manipulated by using the generated accessor methods. In principle, it is also possible to manipulate the underliying data implementation directly but the current version of JBind is not thoroughly tested for this kind of use. In addition, nearly no constraints are checked when manipulating the data implementation directly.
4.4.1 Validation
[Definition: During manipulation only local constraints are enforced, i.e. constraint that consider only the simple content of elements or attributes. Amongst these constraints are the inherent constraints of simple types, constraints based on facets, and fixed values.] [Definition: After manipulation the global constraints can be checked by calling the validateData method of the JBindFacade. Global constraints consider XML data as a whole. They contain identity constraints, occurence constraints, and XPath constraints.]
4.4.2 Adding, Creating, and Removing
Studiying the generated accessor methods one may wonder why there are no methods for adding attributes or elements. The reason lies in the relationship between types and declarations in the JBind framework. A type has not enough information to instantiate a data class because it has no information about fixed/default values. Therefore data classes are instantiated using declarations.
The declaration to be used for instantiating a data class depends on the "position" of the data in the XML structure, i.e. it depends on its enclosing data class. XML schema requires that content models must not contain two element declaration with the same name but different types or value constraints. Therefore the element declaration to use for instantiating a data class is not dependent on the index of an element in the sequence of enclosed elements. Therefore if an element is to be added to a data object then the data object is asked to return a corresponding element declaration. Newly created elements are appended to the current content of the data object. Similar comments apply to attributes.
The described approach works fine if there is already a data class to which attributes/elements
are added. In order to create an top-level element, i.e. an element that is not enclosed inside
a data class another mechanism is needed.
[Definition: The schema factory of a schema is
used to instantiate top-level data classes.] The schema factory is defined by specifiying
its type using the factoryType binding attribute (cf. 3.3.4 Other Binding Attributes).
The schema factory acts as a normal data class to create elements.
The difference to a normal data class is that the schema factory creates top-level elements.
Therefore the content model of a schema factory type must contain only references to top-level
elements and no element declarations or element wildcards.
If a factoryType is specified for a schema then an instance of that type
is created that can be accessed by the method
getFactory()
of the schema. The following example shows the usage of a schema factory. The example reuses the schema
presented at 3.4 Example Schema.
package org.jbind.example.meansOfTransport;
import java.math.BigDecimal;
import java.net.URL;
import org.jbind.xml.core.cmp.ISchema;
import org.jbind.xml.facade.JBindFacade;
import org.jbind.xml.msg.XmlException;
/**
* Example showing the usage of the schema factory.
*/
public class TruckCreation {
public static void main(String[] args) {
URL url = TruckCreation.class.getResource("meansOfTransport.xsd");
try {
ISchema schema = JBindFacade.readSchema(url);
IFactoryData factory = (IFactoryData)schema.getFactory();
ITruck truck = factory.createTruck();
truck.setNumberOfWheels(7);
truck.setFuelType("water");
truck.setConsumption(12.0);
truck.setLoadCapacityInTons(new BigDecimal("30"));
} catch (XmlException e) {
e.printStackTrace();
}
}
}
|
JBind allows no indexed access of elements in a content model. The reason is that content models in XML schema are very flexible and allow elements to appear in complex ways for which a simple indexed access seems not to be appropriate. JBind allows only to iterate through elements in document order. Elements that are substitutes (i.e. elements that are in the substitution group of an element contained in a content model) are included in the iteration.
The iterator used is a ListIterator allowing the forward and backward navigation. In addition,
elements can be removed by invoking the remove method of the iterator.
Note:
It would be nice to generate classes that reflect the content models and thereby allow to navigate through the content. Such classes would also allow to create new elements at specific positions in a content model. This might be a further direction of development of JBind if the user community demands that feature.
4.4.3 Wildcard Attributes and Elements
Wildcard attributes and elements are accessed by methods inherited from the IAnyTypeData interface. The usage of some of these methods is illustrated in 6.2 BabelFish SOAP Client where the wildcard elements inside SOAP bodies are accessed. The relevant methods are:
| method | description |
|---|---|
IAnyTypeData getAttribute_(String aNamespace, String aName) |
Gets an attribute. |
Iterator iterAttributes_(String aNamespace, String aName) |
Iterates attributes. |
setAttribute_(String aNamespace, String aName, IAnyType anOverloadingType, String aValue) |
Sets an attribute. |
Iterator iterElements_(String aNamespace, String aName) |
Iterates elements. |
createElement_(String aNamespace, String aName, IAnyType anOverloadingType, String aSimpleContent) |
Creates an element. |
5 Conformance and Extensions
The conformance of JBind was checked by using the W3C XML Schema Test Collection available at http://www.w3.org/2001/05/xmlschema-test-collection.html with all the test cases available in July 2002. All test cases were passed except some few test cases that seem to be incorrect. In addition, JBind contains a collection of scenarios that are used to test the schema compiler and that are at the same time additional test cases for conformance.
Therefore to the best knowledge of the author JBind seems to be conformant with the XML schema specification with the exceptions reported in the next section.
5.1 Missing Features
The ENTITY and ENTITIES types are supported only syntactically, i.e. it is only checked that data of type ENTITY or ENTITIES is a valid NCName or a list of valid NCNames, respectively. It is not checked that the NCNames match unparsed entity declarations.
5.2 Extensions
The XML schema specification allows arbitrary elements to appear inside
appinfo elements. This mechanisms is used by JBind for extending
the expressiveness of schemas and to provide additional information for code
generation.
[Definition: An extension element
is an element in the JBind namespace
that appears inside an appinfo element].
The following schema shows the various extension elements of JBind. They are explained in
the next sections.
<?xml version="1.0" encoding="UTF-8"?>
<schema
xmlns="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
xmlns:jb="http://www.jbind.org"
targetNamespace="helloWorld"
xmlns:t="helloWorld"
jb:package="helloWorld">
<complexType name="Country">
<annotation>
<appinfo>
<jb:key name="cityIndex">
<selector xpath="t:city"/>
<field xpath="../@countryId"/>
<field xpath="@cityId"/>
</jb:key>
<jb:xPathMethod name="countrySummary"
xpath="concat('country ', @countryName, ' has ', count(t:city), ' cities.')"
type="string"/>
</appinfo>
</annotation>
<sequence maxOccurs="unbounded">
<element name="city" type="t:City"/>
</sequence>
<attribute name="countryId" type="NMTOKEN" use="required"/>
<attribute name="countryName" type="string" use="required"/>
<attribute name="area" type="nonNegativeInteger"/>
</complexType>
<complexType name="City">
<attribute name="cityId" type="NMTOKEN" use="required"/>
<attribute name="cityName" type="string" use="required"/>
</complexType>
<complexType name="Person" jb:hasBehaviour="true">
<annotation>
<documentation xml:lang="x-javadoc">
A person has the method "sayHello".
</documentation>
<appinfo>
<jb:keyref name="city" refer="t:cityIndex" jb:referencedType="t:City">
<selector xpath="."/>
<field xpath="@countryId"/>
<field xpath="@cityId"/>
</jb:keyref>
<jb:xPathConstraint
test="(@extraterrestrial='true' and not(@countryId) and not(@cityId)) or (@countryId and @cityId)"/>
</appinfo>
</annotation>
<attribute name="personName" type="string" use="required"/>
<attribute name="countryId" type="NMTOKEN"/>
<attribute name="cityId" type="NMTOKEN"/>
<attribute name="extraterrestrial" type="boolean" default="false"/>
</complexType>
<complexType name="World" jb:hasBehaviour="true">
<annotation>
<appinfo>
<!-- Counts all countries. -->
<jb:xPathMethod name="countries" xpath="count(.//t:country)" type="number"/>
<!-- Selects all countries. -->
<jb:xPathMethod name="allCountries" xpath=".//t:country" type="select"/>
<!-- Counts all persons. -->
<jb:xPathMethod name="persons" xpath="count(.//t:person)" type="number"/>
<!-- Selects all persons. -->
<jb:xPathMethod name="allPersons" xpath=".//t:person" type="select"/>
<!-- Sums the area of all countries. -->
<jb:xPathMethod name="totalArea" xpath="sum(.//t:country/@area)" type="number"/>
</appinfo>
</annotation>
<choice maxOccurs="unbounded">
<element name="country" type="t:Country"/>
<element name="person" type="t:Person"/>
</choice>
<attribute name="nbSetupAndTearDownLevels" type="int" use="required"/>
</complexType>
<element name="world" type="t:World"/>
</schema>
|
5.2.1 Identity Constraints on Types
Key, unique, and keyref identity constraints of XML schema are applicable only
on elements and not on types. A natural extension is to allow these
constraints also for types with the semantic that each element of such
a type is constrained accordingly.
Identity constraints on types are specified by three extension elements
with the names: key, unique, and keyref.
All these elements have the same attributes and content as the
corresponding elements for defining identity constraints on elements. Key and unique constraints have an additional
scope attribute that is described below.
XPaths in XML schema are of a restricted form. They can only access descendants of nodes and not their ancestors or siblings. JBind allows unconstraint XPaths for selectors and fields in identity constraints on types. This feature allows to handle the situation adequately where some elements are unique inside a specific context, i.e. inside enclosing elements. The key of such elements is simply formed by fields from the elements and their ancestors.
This feature is used in the example schema at the Country type to build an index of cities
inside their countries. The relevant definition is repeated here for convenience:
<complexType name="Country">
...
<jb:key name="cityIndex">
<selector xpath="t:city"/>
<field xpath="ancestor::*[@countryId]/@countryId"/>
<field xpath="@cityId"/>
</jb:key>
...
</complexType>
|
The first field XPath is the interesting one. It selectes amongst the ancestors of a city element
that one that has a countryId attribute. (There must be exactly one such element. Otherwise
an exception is raised.) It would also have been possible just to access
the parent node by the XPath "../@countryId". The first variant is more robust
because it is not so dependent on the structure. It still works for example if regions are introduced
between countries and their citites.
Note:
An XPath like "ancstor::t:country/@countryId" would also work but is not
recommended because the name of elements that will be of type Country is not known. In XPath 2.0
there is a possibility to check elements for their types with an instanceof operator.
This will be the preferred solution in future.
The scope attribute of key and unique constraints can take two possible values:
-
scope="global": This is default. All elements of a type with global key or unique constraint are inserted into a global index for that constraint. Keyref constraints reference entries in this index. -
scope="local": A local index is created if an element with a local key or unique constraint is encountered during validation. The created index can be referenced only from the element itself or from descendents of the element. A local key or unique constraint can not be referenced from parent elements or siblings. Sibling elements of the same type have corresponding indices of their own. If an element of the same type occurs as a descendent then the local index is shadowed by a new local index for the descendent element.Note:
Local key or unique constraints are useful if elements are to be indexed in different contexts. No care must be taken that the keys are globally unique. They must only be unique in their subtree.
5.2.2 XPath Constraints
The xPathConstraint extension element
uses XPaths to specify constraints on
types. The element has two attributes:
-
select. Optional attribute that contains an XPath that is used to select the data objects to be tested. The XPath is evaluated relative to the current data object, i.e. the data object on whose type the XPath constraint is imposed. If noselectattribute is present then the current data object is selected. -
test. An arbitrary XPath that is evaluated to a boolean. The XPathConstraint is statisfied iff its XPath evaluates totruefor all selected data objects.
Note:
XPath constraints are equal in concept to the assert mechanism of [Schematron].
The Person type in the example schema uses an XPath constraint to check the cooccurrence
of attributes. The select attribute is used only for demonstration because its value
corresponds to the default. The relevant part is repeated here for convenience.
<complexType name="Person" jb:hasBehaviour="true">
...
<jb:xPathConstraint select="."
test="(@extraterrestrial and not(@countryId) and not(@cityId)) or (@countryId and @cityId)"/>
...
</complexType>
|
5.2.3 XPath Methods
The xPathMethod extension element
can be used to have the schema compiler generate methods that evaluate XPaths.
The xPathMethod element has the following attributes:
name. Required attribute for naming the method.xpath. Required attribute for the XPath to evaluate.-
type. Optional attribute for specifiying the method type. The method type determines how the result of evaluating the XPath is interpreted. Depending on the method type the generated method has different return types. The method type is also used as a prefix for naming the generated method. The following method types are supported:select(default). Returns an iterator of the selected data objects.fetch. Returns a data object that is selected by the XPath. If the XPath selects more than one data object then an exception is raised.test. The XPath is evaluated to aboolean.number. The XPath is evaluated to adouble.string. The XPath is evaluated to aString.
The example schema contains a number of XPath methods that are used in section 6.1 "Hello World!"
and that are not explained here. For demonstration the following concise schema is presented
that contains an arbitrary nested element that has a number
and a selected attribute. In addition, an instance document and a code snippet
that calls the generated XPath methods is shown. Note the namespace prefixes in the XPaths.
<?xml version="1.0" encoding="UTF-8"?>
<schema elementFormDefault="qualified" targetNamespace="xPathMethods"
xmlns="http://www.w3.org/2001/XMLSchema" xmlns:jb="http://www.jbind.org"
xmlns:t="xPathMethods">
<element name="element">
<complexType>
<annotation>
<appinfo>
<jb:xPathMethod name="allElements" xpath=".//t:element" type="select"/>
<jb:xPathMethod name="totalSum" xpath="sum(.//t:element/@number)" type="number"/>
<jb:xPathMethod name="overview"
xpath="concat('There are ', count(.//t:element[@selected]), ' selected elements.')"
type="string"/>
<jb:xPathMethod name="totalAndSelectedSum"
xpath="sum(.//t:element/@number) > 2 * sum(.//t:element[@selected]/@number)"
type="test"/>
<jb:xPathMethod name="maximum"
xpath=".//t:element[@number and not(@number < //t:element/@number)]"
type="fetch"/>
</appinfo>
</annotation>
<sequence>
<element ref="t:element" minOccurs="0" maxOccurs="unbounded"/>
</sequence>
<attribute name="number" type="decimal"/>
<attribute name="selected" type="boolean"/>
</complexType>
</element>
</schema>
|
| instance document | junit test code | ||
|---|---|---|---|
|
|
Note:
This note is based on ideas that are well-elaborated in [Generative Programming] pp. 259-262.
A common problem with OO programs is the coupling between behaviour and object structure. OO programs tend to contain a lot of small methods that do no or very little computation and call other methods in other objects. This is a consequence of the law of Demeter that states that a method should access only self, local/instance variables, and arguments.
An alternative to having lots of small "information passing" methods is not to
obey the law of Demeter and access "remote" objects by invokation chains
(e.g. object.part1().part2().part3()). This makes lots of small
"information passing" methods unneccessary but at the same time
"hardwires" the object structure within methods.
The usage of XPath methods (especially of the select or fetch type)
can remedy this dilemma. The object structure can be hidden from methods by defining XPath methods
for "remote" object access.
5.2.4 References between Instance Documents
Validation in XML is always concerned only with the validity of single instance documents. A consequence is that attributes of type IDREF or IDREFS or type key ref constraints can only reference data that is contained in the same instance. A natural extension is to allow references between instance documents. A common example would be to have definitions in one instance document and to reference these definitions from other instance documents.
[Definition: JBind uses a so called data context to allow references between instance documents. On the one side a data context stores indexed data (i.e. data that has an ID attribute, a type key, or type unique constraint) and on the other side it stores open references (i.e. data with an IDREF/IDREFS attribute or with a type keyref constraint) while a data tree is validated. The same data context can be used to validate several instance documents thereby allowing references between instances.]
Note:
The current implementation of a data context is not thread safe.
In the example schema of section 3.4 Example Schema the MeansOfTransport
type is defined to have a manufacturer attribute of type IDREF. The
Manufacturer has a corresponding attribute of type ID. We deal with
this situation by first reading a file that contains manufacturers and then a file containing
means of transports. An example consisting of 2 XML files and a snippet of Java Code that reads
and processes them is shown below.
| Manufacturers | Means of Transports | ||
|---|---|---|---|
|
|
||
| Java Code | |||
|
|||
6 XML Code
[Definition: The term XML Code is used to denote an instantiated data class structure that may posses some behaviour, i.e. some of the data classes may be derived from manually implemented behaviour classes.] In most cases XML code is the result of unmarshalling an instance document. JBind offers functionalities for common situations of XML code: configuration code and application code.
[Definition: XML Configuration Code
is XML code where the root data class must implement the
IConfiguration interface and
where some of the contained data classes may implement the
ISetupAndTearDown interface.]
Configuration code is managed by the ConfigurationCode
class that has functionalities to read in configuration data, to set it up, and to tear it down after usage.
Configuration code can either be instantiated directly or by using the
createConfigurationCode
methods of the JBindFacade.
The setup and the tear down processes visit every data object in the
XML configuration code
and call the setup or tearDown method of each data object that implements the
ISetupAndTearDown
interface, respectively. Children are setup before their ancestors and ancestors are teared down before their children.
These processes may have several levels, i.e. the structure is visited several times whereby a level counter
is incremented during a setup process or decremented during a tear down process. This allows to handle situations where
ancestors must be setup before their children or children must be teared down before their ancestors.
[Definition: XML Application Code is derived from
XML configuration code by adding an execute method.
Application code must implement the
IApplication interface
where the execute method is defined.]
XML application code can be executed by using the JBindFacade
or by using the main method of the ApplicationCode class:
java org.jbind.xml.code.ApplicationCode -url <applicationUrl> |
6.1 "Hello World!"
The schema presented in section 5.2 Extensions is used as a base for an XML application.
This is done be implementing the
IApplication
and the
ISetupAndTearDown
interfaces in the
World
and
Person.
behaviour classes, respectively.
Note that the getNbSetupAndTearDownLevels method is realized by having a corresponding
attribute in the World type.
The two classes, an application instance document, and the output of the application are shown below.
| World | Person | ||
|---|---|---|---|
|
|
| XML Application (world.xml) | Application Output (with 2 setup/tear down levels) | ||
|---|---|---|---|
|
|
6.2 BabelFish SOAP Client
A simple SOAP client for the AltaVista BabelFish service is implemented as another example of an XML application. This service is based on SOAP 1.1 (cf. [SOAP-1.1]).
In order to have JBind "talk" SOAP 1.1 some special steps have to be taken.
The reason is that SOAP 1.1 is not based on [XSD-0] but on an
intermediate working draft. Two schema documents
xml-schema-1999.xsd and
xml-schema-instance-1999.xsd
are included that contain the definitions from these namespaces that are
necessary to talk with the BabelFish service.
The soap11.xsd
schema document contains the type Client whose attributes contain the information that
is necessary to talk to a SOAP service. In addition, it has a behaviour class
where the execute method of the XML application is implemented. The Client
class contains only SOAP specific functionalities. It creates a SOAP envelope, validates the envelope,
marshals the envelope for transmission, does the networking, and unmarshals the result.
All service dependent parts are delegated
to an envelopeHandler that must be configured as an element of the client. The following
code snippet shows the corresponding lines from the Client class:
ISchema schema = Schemas.getInstance().getSchema("http://www.jbind.org/examples/soap11");
IFactoryData factory = (IFactoryData)schema.getFactory();
IEnvelopeData envelope = (IEnvelopeData)factory.createEnvelope();
getEnvelopeHandler().fillEnvelope(envelope);
JBindFacade.validateData(envelope, null);
URL url = new URL("http", getHost(), getPort(), getFile());
HttpURLConnection connection = (HttpURLConnection)url.openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "text/xml");
connection.setRequestProperty("SOAPAction", getAction());
connection.setDoOutput(true);
OutputStream os = connection.getOutputStream();
JBindFacade.marshal(os, "UTF-8", true, envelope, null, null);
os.flush();
connection.connect();
InputStream is = connection.getInputStream();
InputSource inputSource = new InputSource(is);
IEnvelopeData result = (IEnvelopeData)JBindFacade.unmarshal(inputSource, null);
getEnvelopeHandler().acceptResult(result);
|
The BabelFish specific part includes a schema document with the defintions of the SOAP body blocks
of the request/response messages and of the BabelFishEnvelopeHandler. In addition,
the methods to fill a SOAP envelope with a corresponding request element and to accept the response
have to be implemented. For brevity, only the definition of the soap client, the implementation
of the BabelFishEnvelopeHandler, the XML application code, and the result of running the
application is shown here:
| SOAP Client and Result | BabelFish Envelope Handler | ||||||
|---|---|---|---|---|---|---|---|
|
|
||||||
| XML Application Code | |||||||
|
|||||||
Note:
The schemaLocation attribute in the XML application code has the effect that
all listed schema documents are loaded.
If the schema documents would not be loaded by
this mechanism then the location of the schema documents would have to be configured
(cf. 7.8 How Instances are Linked with their Schemas).
6.3 Maze Game
The maze game is realized by a simple web application implemented mainly
by the MazeServlet
class. The maze structure is specified by a schema consisting of rooms and exits
linking these rooms. The servlet is configured by a maze instance document and
allows to "move" between the different rooms. The HTML view of a room is
generated by a stylesheet using an XSLT processor. The room data (i.e. its name
and exits) is supplied to the stylesheet by creating a SAXSource for the data.
| Maze Schema | Maze Instance and XSLT-Template | ||||||
|---|---|---|---|---|---|---|---|
|
|
| Init Method of MazeServlet | Process Request Method | ||
|---|---|---|---|
|
|
The JBind distribution contains the maze.war file that can directly
be deployed in any servlet container. Using JBoss in its standard configuration
it can be accessed under the URL http://localhost:8080/maze/.
7 JBind Configuration
JBind is configured using Java preferences that are managed by the Config class. This class offers possibilities to reset, import, export, and modifiy the preferences via the command line. See the JavaDoc of the Prefs class for a complete description of the command line interface. The default configuration of JBind can be viewed by first resetting the configuration and then exporting it into a file. The following command line performs this task:
java org.jbind.xml.Config -reset -export config.xml |
The used preferences are configured by system properties[1]:
| property | possible values | default | description |
|---|---|---|---|
jBindPreferenceTree |
system, user |
user |
Determines if the system or the (current) user preference tree is used. |
jBindInitConfig |
true, false |
true |
Determines if the configuration is initialized. If set to true the configuration is either reset to its default or a configuration resource is imported. |
jBindConfig |
URL or filename |
Relevant only if the jBindInitConfig property is set to true.
If the specified resource contains the substring "://" then it is used as a URL
to access the configuration resource. Otherwise the getResourceAsStream method
of Config.class used to access the resource.
|
7.1 Validation Options
| switch | possible values | default | description |
|---|---|---|---|
strictSchemaValidation |
true, false |
false |
JBind allows arbitrary particles to occur inside "all" model groups.
If set to true then only element declarations with a maxOccurs
of 1 are allowed.
|
checkLanguageCode |
true, false |
false |
Determines if the language code in language data objects is checked. The known language codes
are stored in the files languages-2.txt
and languages-3.txt.
|
checkCountryCode |
true, false |
false |
Determines if the country code in language data objects is checked. The known country codes
are stored in the file countries.txt.
|
7.2 ClassLoader Configuration
JBind uses the class loader that loaded JBind or the context ClassLoader to load the classes during instantiating instance documents. It can be configured if the JBind class loader is tried first and then the context class loader or vice versa.7.3 Regular Expressions
The name of a class can be configured that is used to create regular expression. The configured class must implement the IRegExFactory interface.
7.4 XPath
The name of a class can be configured that is used to create XPaths. The configured class must implement the IXPathFactory interface. The used XPath factory is related to the data implementation factory because (normally) XPaths are evaluated base on the data implementation.
7.5 Data Implementation Factory
The name of a class can be configured that is used to create data implementations. The configured class must implement the IDataImplFactory interface. The used data implementation factory is related to the used XPath factory (see above).
7.6 Namespace to Package Mapping
A mapping from namespaces to package names can be configured. This mapping is used to define the schema package of schemas for which no other package information is available. For the precedence of package information see 3.3 Parameterizing the Code Generation.
7.7 Entity Resolver, Import, and Include
The name of the class can be configured that is used to resolve entities for SAX parsers.
The configured class must implement the org.xml.sax.EntityResolver interface.
In many cases the default mechanism used by JBind is sufficient.
[Definition: Entities are resolved with the help
of XML catalogs (cf. [XML Catalogs]). In short, XML catalogs can resolve entities given
their public or system identifiers and they can map URIs into URIs.]
JBind uses XML catalogs to resolve entities during SAX parsing and to map namespace URIs into
schema document URLs.
The keys of the xmlCatalogs
node in the configuration specify the XML catalogs to be used. The value a key maps into specifies
how a catalog is loaded. Two modes are supported: 1. Catalogs might be accessed by a class loader using the
Config.class.getResource method
(LOAD_BY_CLASS_LOADER) or 2. by URLs
(LOAD_BY_URL). Relative URLs are resolved
relative to the current user home directory. In the default configuration JBind tries to load the following catalogs:
| Location | Load Mode | description |
|---|---|---|
| /org/jbind/catalog.xml | class loader | JBind catalog (for internal use) |
| /catalog.xml | class loader | application catalog (for free use by applications) |
| .catalog.xml | URL | user catalog (for free use by user) |
The standard configuration of JBind allows the integration of arbitrary XML catalogs very easily because of the predefined application and user catalog. In order to have an XML catalog used by JBind simply name it "catalog.xml" and make it accessible to the class loader or name it ".catalog.xml" and place in the user home directory.
When a namespace is imported by an import element then the location of the schema document for
the namespace is determined by trying several options in sequence. The algorithm first determines a
resulting URL and then an effective URL that is finally used to access the schema document.
The options are:
If the namespace URI is mapped into a URL by an XML catalog entry then this URL is used as the resulting URL.
If the
importelement has aschemaLocationattribute then this URL is used as the resulting URL.Otherwise the namespace URI is used as the resulting URL.
The situation, when a schema document of a namespace is introduced in an instance document
using the xsi:schemaLocation or xsi:noNamespaceSchemaLocation attribute
is treated similarly to importing namespaces:
If the namespace URI is mapped into a URL by an XML catalog entry then this URL is used as the resulting URL.
Otherwise the specified URL is used as the resulting URL.
When a schema document is included or redefined by an include or redefine element, respectively,
then it is also tried to map the URL specified by the schemaLocation attribute using the XML catalog.
Note:
JBind uses the XML catalogs implementation of Norman Walsh (cf. A Installation) that has additional configuration possibilities. For details refer to the documentation of that package.
7.8 How Instances are Linked with their Schemas
When an instance document is unmarshalled then the corresponding schema information must be available. JBind offers several possiblities to link instance documents with their schemas.
-
By using the
xsi:schemaLocationandxsi:noNamespaceSchemaLocationattributes in instance documents.This situation is described in section 7.7 Entity Resolver, Import, and Include. In short, the URL of a schema is either looked up in an XML catalog based on either its namespace or the specified URL. If the lookup does not return a URL then the specified URL is used.
-
By explictly reading in and registering schemas before instance documents refer to them.
While an instance document is unmarshalled JBind looks up schema information for every globally scoped element or attribute using the
Schemassingleton. A schema can be read in by theJBindFacade.readSchemamethod and registered by theSchemas.setSchemamethod.